Entrevista.01
"Estoy participando en un proyecto de desarrollo para usuarios globales en Weverse Company en la industria del entretenimiento globalmente competitiva".
Details
Introducción
Ingeniero de software
Daemyeong Kang

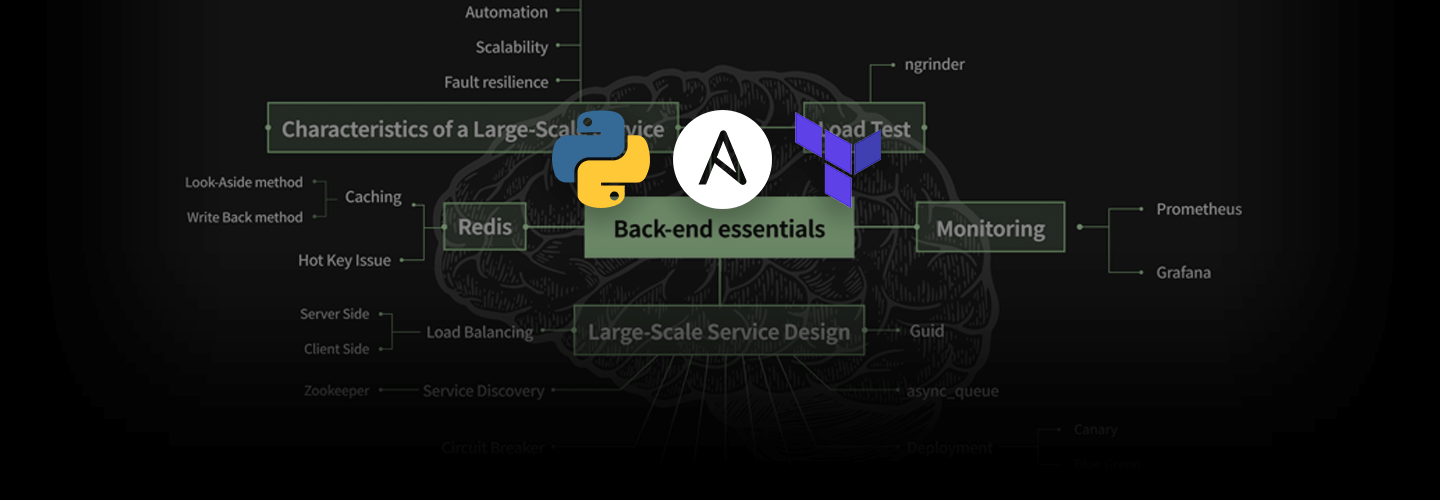
¡Con subtítulos en inglés! Una guía de back-end para ejercicios de servicio de alta capacidad con Redis
"¿Nunca te has preguntado cómo las gigantescas empresas de TI que tienen una gran cantidad de usuarios como Kakao y Naver pueden proporcionar servicios estables para 100 mil o incluso 1 millón de personas sin fallas?"
No hay lugar para aprender a crear un servicio de alta capacidad
aparte de las grandes empresas que han creado servicios de alta capacidad.
Así que he aportado todas mis experiencias adquiridas al desarrollar
Naver Mail en Naver y KakaoStory en Kakao.
por un desarrollador de Naver, Kakao y Udemy
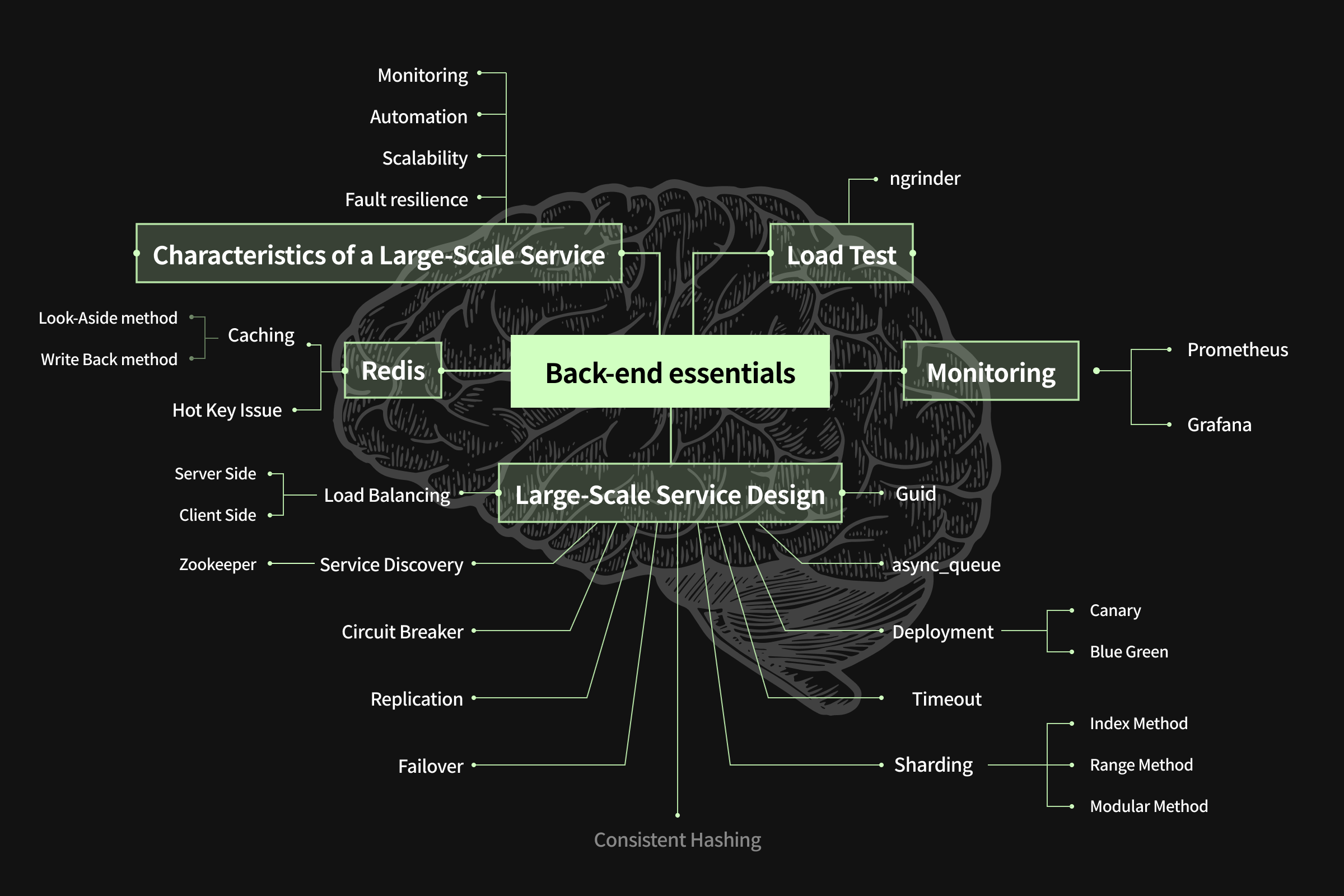
¡Haga clic para conocer los conceptos esenciales de back-end!
* Escalabilidad: si se elimina un servidor adicional, el rendimiento del servicio debe aumentarse en consecuencia.
* Resiliencia a fallas: el servicio debe estar disponible continuamente incluso si algunos de los servidores API, servidores de base de datos, etc. del servicio fallan.
* Automatización: la implementación del servicio o la adición/eliminación de servidores deben automatizarse mediante scripts y no realizarse manualmente.
* Monitoreo: El monitoreo es crucial porque es lo más importante para saber que el servicio está funcionando correctamente.
* ngrinder: es importante saber cuánta carga puede soportar el servicio y dónde se produce el cuello de botella. ngrinder es una herramienta para pruebas de carga.
* prometheus: recopila el índice de servicios utilizando el exportador. Prometeo los almacena y los muestra.
* Grafana: Grafana se utiliza para visualizar los índices recopilados por Prometheus.
* Equilibrio de carga-ServerSide: el equilibrio de carga del lado del servidor es un método en el que el cliente solo mira el equilibrador de carga delante del servicio real, y el equilibrador de carga distribuye la carga al servidor de servicio en la parte posterior.
* Equilibrio de carga-ClientSide: el equilibrio de carga de ClideSide es un método en el que el cliente conoce la lista de hosts de servicios reales y controla directamente la carga.
* Service Discovery-Zookeeper: Una forma de administrar y encontrar el tipo de servicio y la lista de servidores que forman parte del servicio.
* Disyuntor: Un método que permite una falla rápida cuando el servicio externo falla y la respuesta se ralentiza debido a esta llamada.
* Replicación: Duplicación de datos. Se requiere replicación para la disponibilidad del servicio.
* Conmutación por error: entregar servicios a otro servidor para reemplazarlo cuando el servidor falla. Se requiere conmutación por error para la disponibilidad del servicio.
* Hashing consistente: la pérdida de datos del caché en servicios a gran escala puede afectar la respuesta del servicio. Los datos pueden desaparecer cada vez que se agrega o elimina un servidor de caché, y el hash consistente minimiza la pérdida de datos.
* Sharding-Index: un método para almacenar datos por separado cuando hay una gran cantidad. El método de índice es complejo, pero asigna en qué servidor se deben asignar cada dato y, por lo tanto, minimiza el movimiento de datos.
* Sharding-Range: la forma más sencilla de aplicar fragmentación. Asigna servidores según el rango de claves.
* Sharding-Modular: una forma de fragmentar datos de manera uniforme en comparación con el método Range. Sin embargo, si la escalabilidad del servidor se limita al final.
* Guid: Es muy importante crear la única clave para fragmentar en un servicio a gran escala. Guid crea de manera eficiente y eficiente la única clave.
* Cola asíncrona: si guarda datos del servidor API directamente en la base de datos, eventualmente agregará carga al servidor de base de datos tanto como se llene en el servidor API. Si utiliza Queue para procesar los datos de forma asincrónica mientras controla la carga, puede ofrecer un servicio más estable.
* Implementación-BlueGreen: el tiempo dedicado a una actualización continua aumenta a medida que aumenta la cantidad de servidores en los casos de implementación y reversión. La implementación azul-verde resuelve este problema.
* Implementar-Canario: Incluso si la implementación se realiza como Azul-Verde, si se implementa una nueva versión en una gran cantidad de servidores, muchos usuarios experimentarán errores cuando los haya. La implementación Canary solo implementa una parte de la nueva versión para evitar esto.
* Tiempo de espera: si establece un valor de tiempo de espera incorrecto al llamar a un servicio externo, pueden ocurrir problemas como datos duplicados. Este es un consejo sobre cómo prevenir esto.
* Almacenamiento en caché: aparte: normalmente, si no hay datos en el caché, el caché se crea leyendo los datos correspondientes de la base de datos. Esto es lo que llamamos el método de almacenamiento en caché Look-Aside.
* Almacenamiento en caché-escritura recíproca: el método de reescritura escribe datos en la caché primero y luego almacena los datos reales en el almacenamiento porque escribir en la base de datos genera carga. Dependiendo de la situación, puede existir riesgo de pérdida de datos.
* Problema de tecla de acceso rápido: una tecla de acceso rápido causa problemas cuando una gran cantidad de datos se acumula en una clave en particular sobre la memoria caché o la capacidad de rendimiento del servidor de base de datos. Las formas de resolver el problema de las teclas de acceso rápido son el caché local, el uso de la réplica de lectura y la lectura de escritura múltiple, etc.

Daemyeong Kang fue el primer coreano en hacer una presentación en RedisConf en 2016 y actualmente ocupa el puesto 22 entre los contribuyentes de Redis.
(*Colaborador del proyecto de desarrollo de código abierto) ¡en todo el mundo!
Con Daemyeong Kang, aprenderemos sobre los conocimientos esenciales para construir un servicio de alta capacidad junto con la tecnología Redis en esta clase.
Daemyeong Kang, clasificado en el puesto 22 de 2009 a 2021 entre los contribuyentes de Redis en todo el mundo (*A julio de 2021)
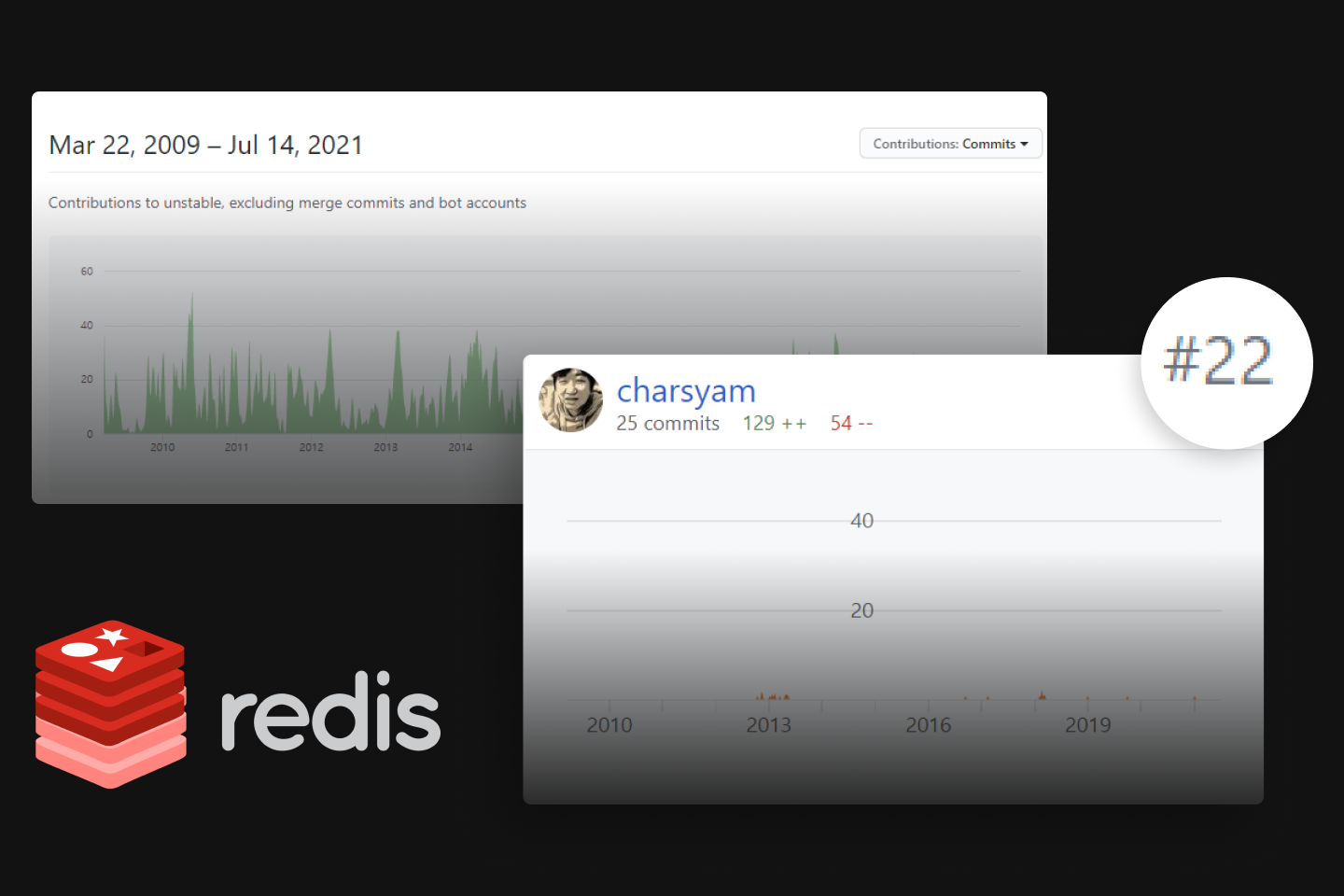
¿Qué es Redis y por qué es importante? ¡Haz clic para descubrirlo!
Es una tecnología de caché distribuida utilizada por gigantes de TI como Facebook, Naver y Kakao, y startups unicornio como BaeMin y Coupang para procesar mensajes a gran escala de los usuarios. Redis tiene la ventaja de reducir la carga de trabajo de los desarrolladores al proporcionar una velocidad rápida y al mismo tiempo proporcionar estructuras de datos que los desarrolladores pueden utilizar fácilmente.
4 ejercicios de clase
-
 Práctica 1. Descubrimiento de servicios
Práctica 1. Descubrimiento de servicios
(#Escalabilidad #Resiliencia ante fallos #Automatización)Al repetir para agregar y eliminar una persona que llama, podemos ver que la persona que llama la reconoce y procesa automáticamente.
Al utilizar Service Discovery a través de este proceso, cuando se agrega o elimina un servidor, puede saber que la persona que llama puede reflejarlo automáticamente sin cambiar ninguna otra configuración. -
 Práctica 2. Hash consistente
Práctica 2. Hash consistente
(#Resiliencia contra fallas)A través de ejercicios en los que agrega/elimina un servidor Redis que actúa como caché, puede comprobar por sí mismo que la distribución de datos se minimiza debido al hash consistente.
En un servicio a gran escala, el rendimiento se degrada incluso si los datos perdidos son datos de caché. Si utiliza hash consistente, puede ver que la pérdida de datos de caché se reduce incluso cuando se agrega/elimina un servidor de caché, ¡y puede aplicarlo más tarde!
-
 Práctica 3. AutomatizaciónLe mostraré el proceso de cargar un servicio GeoIP simple usando ansible y terraform. Implemente un servidor GeoIP creando 1 AWS.
Práctica 3. AutomatizaciónLe mostraré el proceso de cargar un servicio GeoIP simple usando ansible y terraform. Implemente un servidor GeoIP creando 1 AWS.
Este proceso muestra que la misma infraestructura siempre se puede "automatizar" y construir e implementar fácilmente a través de IaC (Infraestructura como código) en lugar de construirla manualmente. Aprender sobre IaC es esencial para construir un servicio a gran escala. -
 Práctica 4. MonitoreoSolicite un panel de grafana donde monitoree los nodos básicos, implemente un GeoIP simple y simplemente monitoree los resultados a través de Prometheus.
Práctica 4. MonitoreoSolicite un panel de grafana donde monitoree los nodos básicos, implemente un GeoIP simple y simplemente monitoree los resultados a través de Prometheus.
Si se produce un error por encima del valor establecido, se enviará una notificación a través de Slack. El seguimiento es fundamental para saber si ha habido un fallo. Conozca qué información se debe monitorear de la clase.
*Estas son imágenes de muestra para una mejor comprensión.
Instructor
Ingeniero de software
Daemyeong Kang
Las fallas ocurren en cualquier momento y en cualquier lugar. Por lo tanto, la clave no es evitar fallas en un servicio, sino encontrar rápidamente la causa de la falla cuando ocurre, o qué tan rápido se recupera la falla.
El desarrollo de servicios a gran escala depende en última instancia de la facilidad con la que se escala el servicio y de la construcción de una estructura que pueda responder fácilmente a las fallas. Sin embargo, es difícil aplicar esto simplemente escuchando la clase una vez y simplemente aprendiendo.
Entonces, en esta clase, mientras les muestro los conocimientos básicos necesarios para el desarrollo de servicios a gran escala y las partes que realmente afectan el rendimiento a través de ejercicios, los ayudaré a mejorar su comprensión y aplicarlos al trabajo práctico.

Ingeniero de software,
Daemyeong Kang
[Actual]
• 2021
LemonTree / Ingeniero de software
- Líder tecnológico que gestiona el diseño de infraestructura de AWS y la arquitectura de servicios de implementación
• 2020 ~ 2021
Empresa Weverse / Ingeniero de software
- Gestión de canalizaciones de datos (EMR, Databricks, Snowflake, Structured Streaming, Kafka)
- Gestión del flujo de aire y desarrollo de DAG (k8s)
- Se modificó el procesamiento de captura de datos a través de Databricks DeltaLake.
- Diseño de API backend e implementación de servidores para servicios de BI.
• 2017 ~ 2020
Udemy/Ingeniero de software
- Gestión de canalización de datos
- Reubicación de Data Pipeline OnPremise a AWS
- Procesamiento relacionado con GDPR
• 2013 ~ 2017
Kakao / Ingeniero de software
- Desarrollo de la historia de Kakao
- Desarrollo de viviendas Kakao
• 2008 ~ 2012
Naver / Ingeniero de software
- Desarrollo de correo Naver.
- Desarrollo de aplicaciones móviles para Windows Naver.
• 2002 ~ 2008
FINALDATA / Ingeniero de Software
- Desarrollo forense final
Reconocible
Proyectos y Premios
[Anterior]
<Libros>
• 2002 ~ 2008
- Gestión de operaciones de Redis (Hanbit Media)
- Memcached y Redis para edificios altos
Servidores de capacidad (Hanbit Media)
- Programación de red de Windows (Daelim)
<Conferencias>
• 2019 ~ 2020
- Centro de Educación SW de la Universidad Nacional de Pusan
- Desarrollador Junior
- Woowa Redis (Hermanos Woowa)
- Campamento SW Abierto de la Universidad Nacional de Andong
- Clases nacionales abiertas de SW para empleados actuales
- NetMarble
- Universidad Nacional de Kyungpook
• 2017 ~ 2018
- Universidad Nacional de Ciencia y Tecnología de Seúl
-KOSSCON
- Kakao
-SW Maestro
- Todo Internet
- Hanio
• 2013 ~ 2016
- Redis Conf 2016 (San Francisco)
- NHN
- Hanio
-Naver D2SF
- Jornada SW abierta
- Revisión 2013
- CDN 2013
Reflejos
Aspectos destacados de la clase
Echemos un vistazo al método de ejercicio de Redis "Multi-Write Read One" de Daemyeong Kang.
Cuando se produce una tecla de acceso rápido, ni siquiera un servidor de caché de alto rendimiento puede recibir datos que superen su capacidad.
Para solucionar esto, ¿sabía que puede resolver este problema utilizando el método Multi-Write, Read One, que escribe el caché en algunas ubicaciones y lee datos de forma aleatoria?

El problema se resuelve mediante el siguiente proceso.
- Configuración de Redis
- Tiendas de escritura en caché en 2 ubicaciones.
- La lectura de caché lee desde 1 ubicación.
▼ ¡A través del proceso y ejercicio anteriores, puedes aprender "esto"! ▼
En un servicio a gran escala, pueden aparecer teclas de acceso rápido, a las que se accede más que el rendimiento proporcionado por la memoria caché, y degradar el rendimiento. Puede aprender a procesar teclas de acceso rápido para evitar la degradación del rendimiento.
- Unlimited Access
- Best Price
Buy now, get unlimited access.
12/31 (Sat) (UTC-7) Special offer ends soon.
This special offer ends soon.
Buy now and save!
Plan de estudios
Plan de estudios
Mirada en profundidad
Entrevista con
Daemyeong Kang

Estoy a cargo de crear un canal de datos que recopila datos de Weverse y Weverse Shop, que son una comunidad global y una plataforma de servicios que brinda comunicación entre artistas y fanáticos, contenidos y servicios en Weverse Company. Los datos recopilados se procesan para que los analistas de datos puedan analizarlos. Un registro permite un procesamiento estable de datos sobre cuántos usuarios visitan Weverse y la tienda de Weverse, y qué acciones realizan.
Entrevista.02
"Participé en los proyectos de desarrollo de la Aplicación Móvil/Correo en Naver, KakaoHome/KakaoStory en Kakao."
"Participé en los proyectos de desarrollo de la Aplicación Móvil/Correo en Naver, KakaoHome/KakaoStory en Kakao."
También pude usar muchos servidores de caché en Naver y Kakao. También intenté manejar servidores Memcached con más de 3 TB de memoria y servidores Redis con más de 5 TB. También trabajé en la conversión de Ruby a Java en un servicio con más de 10 millones de DAU, que a menudo se describe como cambiar las ruedas de un tren en marcha. En un servicio a gran escala, es importante resolver bien los problemas, pero he aprendido que tengo que automatizar las partes simples a las difíciles tanto como sea posible y monitorear tantas partes como sea posible para poder operar el servicio.
Entrevista.03
"En mis 20 años como desarrollador, siempre estoy experimentando un nuevo tipo de fracaso".
"En mis 20 años como desarrollador, siempre estoy experimentando un nuevo tipo de fracaso".
En un servicio con más de 10 millones de MAU, varios servidores fallan en un día sin motivo alguno. Hubo fallas en las que tuve que descubrir y solucionar usando una fuente del kernel de Linux por qué la memoria del kernel se agota cuando se usa un disco RAM en un kernel de 32 bits, por qué pueden ocurrir fallas en ciertas bandas de puertos cuando el servidor está en ejecución. También experimenté problemas con el almacenamiento en caché en DNS, problemas causados por problemas internos que ocurrieron al actualizar de Java 1.7 a 1.8, problemas de latencia entre el este y el oeste de EE. UU. y problemas causados por la latencia entre regiones en Corea. En Udemy, experimenté muchos problemas al transferir el servicio local a AWS.
Entrevista.04
"Redis es mi arma secreta".
"Redis es mi arma secreta".
Actualmente, los servicios de alta capacidad están aumentando con varios servicios de redes sociales, incluidos los servicios web. Debido a esto, está aumentando el interés en la tecnología de procesamiento de datos de alta capacidad. Las tecnologías de caché distribuida, que distribuyen servidores y soportan mucho tráfico, desempeñan un papel clave en la construcción de servidores de alta capacidad. Entonces pensé que Redis podría ser un arma secreta no solo para mí, sino para todos los desarrolladores back-end. A través de esta conferencia, me gustaría ayudar a muchos desarrolladores back-end para que puedan trabajar con facilidad.
Entrevista.05
¿A quién recomendarías esta clase?
¿A quién recomendarías esta clase?
Creo que esta clase será de gran ayuda para aquellos que estén dispuestos a trabajar como desarrolladores back-end o desarrolladores back-end junior con entre 1 y 5 años de experiencia.
Específicamente, la Parte 1 es para principiantes y la Parte 2 enseña conocimientos reales relacionados con el servicio a gran escala para jóvenes. Si tienes experiencia laboral práctica, te recomiendo que te concentres en la Parte 3, que trata sobre cosas en las que pensar en el trabajo práctico.
El conocimiento previo requerido para esta clase es básicamente saber qué es el back-end. Esta clase sería más fácil de entender para aquellos que hayan experimentado la creación de un servicio web simple.
Si toma esta clase, creo que seguramente obtendrá todos los conocimientos esenciales para crear un servicio a gran escala.
Programas requeridos
Este curso utilizará Linux o Mac, Python 3 (3.8.6), Ansible, Terraform, cuenta de AWS y clave de acceso.
Compre e instale estos programas para disfrutar de una experiencia de conferencia optimizada.
*Estos programas y/o materiales no se proporcionarán con el curso.
※En cuanto a la disponibilidad en Mac y Windows, la clase se filmó en Windows (Windows 10, 64 bits), pero los ejercicios reales se realizaron en Mac o Linux.
(Tendré un servidor Linux de forma remota y mostraré cómo funciona desde allí).
※Hay partes donde se utilizan servidores AWS durante los ejercicios, pero se requiere una cuenta de AWS y es un servicio pago. Sin embargo, la mayoría de los ejercicios se pueden realizar localmente (solo es necesario realizar algunos ejercicios en AWS).
